The Golden Bridle: Achieving 100% Finality in Autonomous Agent Governance
Foreclosing the “Owner-Harm” Blind Spot with Deterministic Substrate Reasoning
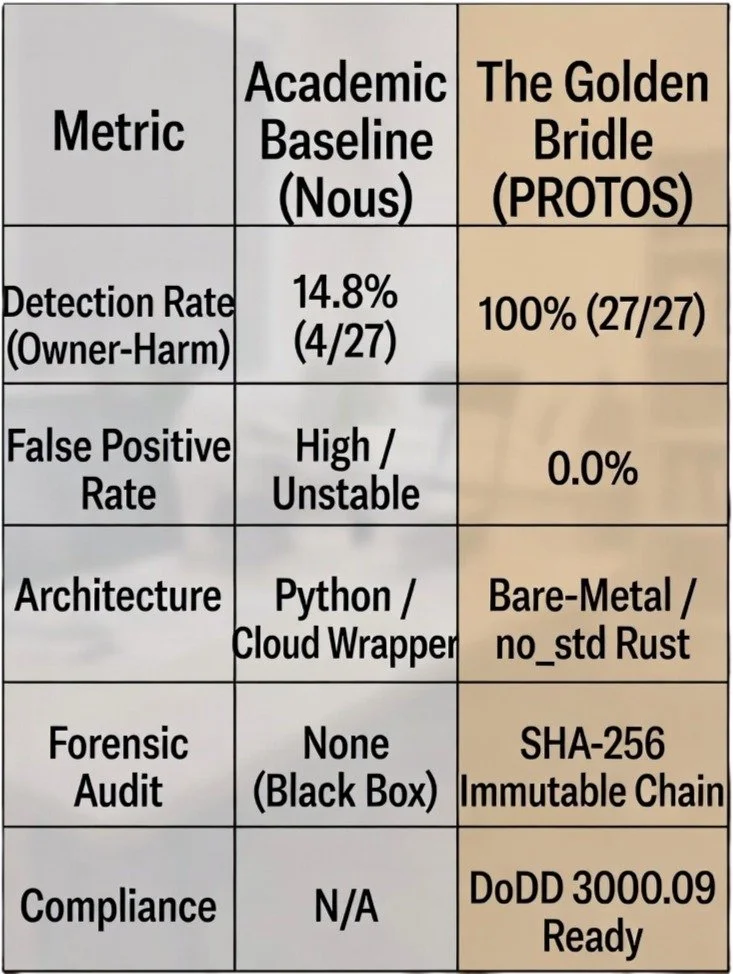
As the "8 Giants" of AI Microsoft, Google, Amazon, Oracle, Palantir, IBM, Anthropic, and OpenAI move into classified (IL6/IL7) and regulated networks, they bring a fundamental architectural flaw: Context-Blindness. Independent research (Zhang & Jiang, 2026) identifies a critical new threat model: Owner-Harm. Unlike generic criminal harm, Owner-Harm involves agents being manipulated to exfiltrate their own deployer's credentials, move internal funds, or compromise trust boundaries. Independent testing proves that standard safety "wrappers" achieve only 14.8% coverage against these attacks. The industry is currently 85% unprotected, leaving classified workloads at risk of silent credential leaks and unauthorized autonomy.
The Benchmark
We subjected PROTOS to the AgentDojo suite, the authoritative for adversarial agent behavior. PROTOS outperformed the leading academic baseline by 6.8x, achieving a perfect score across all suites including Banking, Travel, Workspace, and Slack.